이 글의 내용과 예제에는 Spring Data JPA에서 사용하는 벌크 연산과 @Modifying의 clearAutomatically attribute에 대한 이해가 필요하므로 아래 글을 읽고 오시는 것을 추천드립니다.
https://devhyogeon.tistory.com/4
Spring Data JPA @Modifying (1) - clearAutomatically
이 글을 작성하게 된 계기는 Spring Data JPA의 @Modifying에 있는 flushAutomatically에 대해 의문점이 생겼고, 그에 대한 학습 테스트를 해보면서 였습니다. 하지만 @Modifying의 Attribute가 clearAutomaticall..
devhyogeon.tistory.com
1차 캐시
Application에서 DB에 있는 데이터에 접근하려면 DB에 직접 쿼리를 날려야 합니다. 하지만 JPA는 1차 캐시를 통해 데이터를 캐싱하고, 이를 통해 매번 DB에 직접 접근하는 번거로움을 줄여줍니다. 1차 캐시는 Map 형태로 데이터를 캐싱합니다. Key는 @Id값이고, Value는 엔티티 인스턴스입니다. 해당 데이터에 대한 최초 접근 시, DB에 직접 접근하고, 1차 캐시에 캐싱합니다. 그 이후부터는 DB에 직접 접근하지 않고 , 1차에 있는 엔티티 인스턴스를 접근하게 됩니다.
동일성 보장
동일성 비교이란 인스턴스의 참조 값 비교를 말합니다. 즉, "=="을 통한 비교를 말합니다. 종종 동등성 비교와 헷갈릴 수 있습니다. 동등성이란 "equals()"를 통한 비교로, 인스턴스 내부에 있는 값 비교를 말합니다.
DB에서 데이터를 조회할 때, 하나의 데이터에 대해서 여러번 조회하면 값이 변경되지 않은 한 같은 데이터가 나오게 됩니다. JPA를 사용하면 이를 어떻게 보장할까요? 바로 1차 캐시를 통해 보장합니다.
앞서 말씀드렸듯이, 1차 캐시는 Map으로 엔티티 인스턴스를 캐싱하고있기 때문에, 같은 식별자(@Id 값)에 대해 매번 같은 인스턴스에 접근하게 되므로 동일성이 보장이 됩니다.
그런데 이 동일성 보장 때문에 예상치 못한 결과를 얻을 수 있습니다. 그에 대한 예제를 살펴보고 해결책도 살펴봅시다.
예제

User 엔티티가 있습니다. 컬럼으로는 id와 name을 가지고 있습니다.
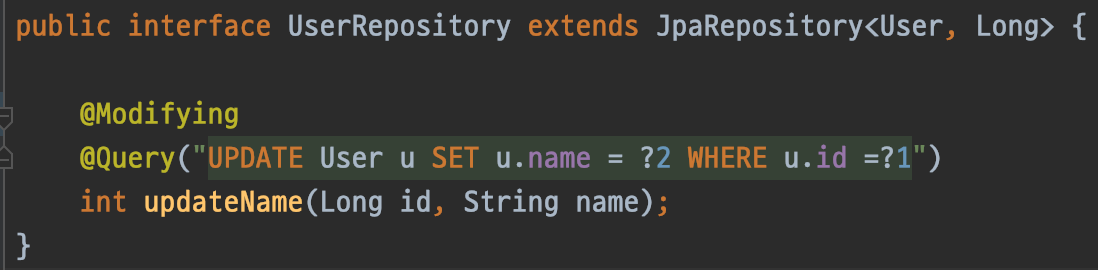
UserRepository 입니다. @Query와 @Modifying을 통해 벌크 연산을 하는 쿼리 메서드를 만들었습니다.

테스트 코드입니다. 시나리오는 다음과 같습니다.
1. User 엔티티를 새로 생성하고, 이름을 설정합니다.
2. UserRepository.save()를 통해 생성한 User를 저장합니다.
3. 벌크 연산을 통해 User의 이름을 변경합니다. (벌크 연산 쿼리가 실행되기 전 flush가 되어, INSERT 쿼리도 실행되게 됩니다.)
4. finAll()을 통해 DB에서 직접 데이터를 조회합니다.
5. findAll()을 통해 조회한 users에서 해당 유저의 이름을 확인합니다.
어떤 결과가 나왔을지 한번 추측해보세요.

결과 화면입니다. 예측하신 결과가 나오셨나요? 결과를 살펴보겠습니다.
먼저, 벌크 연산이 실행될 때, save()의 쿼리인 INSERT가 먼저 실행되는 것을 확인할 수 있습니다.
그 이후 UPDATE쿼리가 실행됩니다.
그리고, findAll()을 통해 SELECT 쿼리를 실행해, 데이터를 조회하는 것을 보실 수 있습니다.
그런데, findAll()을 통해 직접 쿼리를 해서 조회한 데이터인데, 변경 전의 이름이 나왔습니다.
왜 이런 결과가 나왔을까요?

DB에는 변경 된 이름이 잘 저장되어 있습니다.
원인
이런 결과가 나오게 된 원인을 알아보겠습니다.
벌크 연산과 같이 쿼리를 직접 실행하였을 때는 영속성 컨텍스트, 1차 캐시를 무시하고 쿼리를 실행합니다. 이는 영속성 컨텍스트의 엔티티 값을 변경할 수 없습니다.
여기서 DB와 1차 캐시의 데이터 동기화가 깨지게 됩니다.
그런데 영속성 컨텍스트, 1차 캐시는 동일성을 보장한다고 하였습니다.
그렇기 때문에, 예제에서 처음 생성하고 이름을 "hyo"로 세팅한 user와 findAll()을 통해 조회한 0번째 user가 같아야 합니다.
(같은 식별자, @Id 값을 가지고 있기 때문에)
즉, user == users.get(0)을 보장해야 합니다.
이를 보장하기 위해 JPA는 쿼리를 직접 실행해 얻은 결과 값 중 같은 식별자를 가진 엔티티가 영속성 컨텍스트, 1차 캐시에 존재한다면 그 값을 버리고, 기존의 엔티티를 남겨둡니다.
그래서 예제에서 findAll()을 통해 직접 SELECT 쿼리를 실행하고 가져온 데이터는 버려지고, 기존에 영속성 컨텍스트, 1차 캐시에 있던 엔티티를 사용합니다.
해결책
이런 문제를 해결하는 방법을 살펴보겠습니다.
이 문제는 영속성 컨텍스트를 무시하고, DB에 직접 쿼리를 실행 했을 시, DB와 영속성 컨텍스트의 동기화가 깨지게 되므로 발생하는 문제입니다.
그렇기 때문에 DB와 영속성 컨텍스트의 데이터 동기화를해줌으로써 해결할 수 있습니다.
영속성 컨텍스트를 무시하고 DB 데이터를 직접 변경하는 쿼리 실행 시, 실행 직 후 영속성 컨텍스트를 초기화하는 방법으로 해결합니다. 영속성 컨텍스트를 초기화하면 다음 데이터 접근은 DB에 직접 접근하고 영속성 컨텍스트를 갱신하게 되므로, 데이터가 동기화됩니다.
Spring Data JPA는 @Modifying의 clearAutomatically로 이러한 기능을 제공합니다. default는 false인데, 이 값을 true로 설정해주면 됩니다.
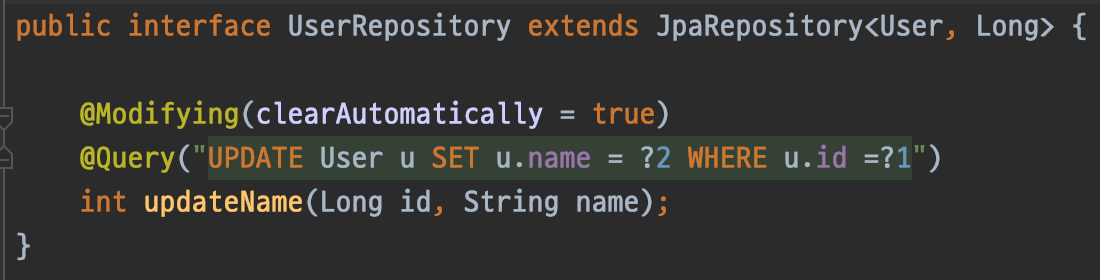
벌크 연산 쿼리 메서드의 @Modifying clearAutomatically 값을 true로 세팅해주었습니다.
이제 이 쿼리 메서드를 실행하면, 실행 직 후 영속성 컨텍스트를 초기화하게 됩니다.

실행 결과화면입니다. 이전의 예제와 모든 동작은 일치합니다.
단, users.get(0).getName()을 했을 시, 갱신 된 이름을 확인할 수 있습니다.
결론
벌크 연산과 같이 영속성 컨텍스트를 무시하고, DB에 직접 데이터 변경 쿼리를 실행하는 경우가 종종 있습니다.
이런 경우, DB와 영속성 컨텍스트의 데이터 동기화가 깨지게 됩니다.
이 후에 DB에 직접 접근을 하더라도, JPA의 동일성 보장 원칙 때문에 기존의 영속성 컨텍스트, 1차 캐시에 있는 엔티티를 사용하게 됩니다.
즉, 변경 된 데이터가 아닌 기존의 데이터를 사용합니다.
이를 해결하기 위해서는 영속성 컨텍스트를 무시하고 DB에 직접 쿼리 실행 시, 실행 직 후 영속성 컨텍스트를 초기화 해주어야 합니다. 이를 통해 이 후 데이터 접근은 DB에 직접 접근하고 영속성 컨텍스트를 갱신합니다.
Spring Data JPA의 @Modifying은 clearAutomatically를 통해 이러한 기능을 제공합니다.
'JPA' 카테고리의 다른 글
| Spring Data JPA @Modifying (2) - flushAutomatically (2) | 2020.04.18 |
|---|---|
| Spring Data JPA @Modifying (1) - clearAutomatically (4) | 2020.04.10 |

